Article : Web Scraping en Python, une valeur ajoutée pour votre entreprise
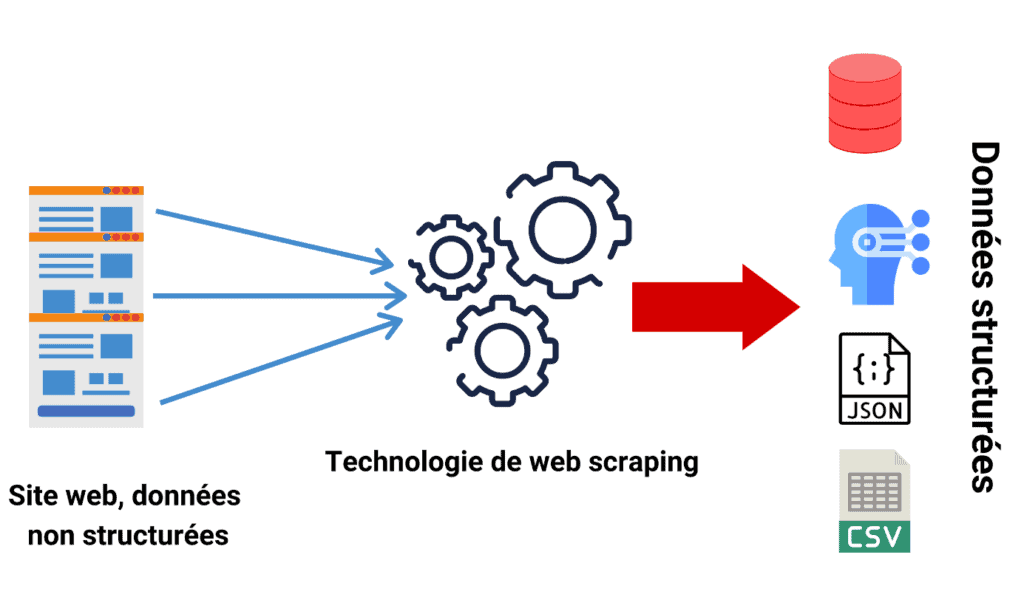
Le web scraping est une discipline consistant à extraire et récolter des données venant du web afin de les exploiter. Cette discipline est facilitée par l'avènement de Python et ses librairies comme Scrapy, Beautiful Soup ou Selenium.
Pourquoi faire du web scraping ?
Le web scraping peut vous aider pour de nombreux projets. En effet, la donnée est considérée comme étant l'or du 21ème siècle, alors avoir un service ou bien même une personne dédié au web scraping autrement dit un "web scraper" habile avec une bonne connaissance métier est une réelle plus value pour votre structure.
Effectivement, vous serez en mesure d'extraire n'importe quelle source de donnée venant du web afin de les intégrer dans votre système d'information pour ensuite pouvoir les exploiter, et ce avec un coût de fonctionnement minimal et une performance assez impressionnante. De plus, vous pouvez mener vos propres agrégations sur les données extraites.
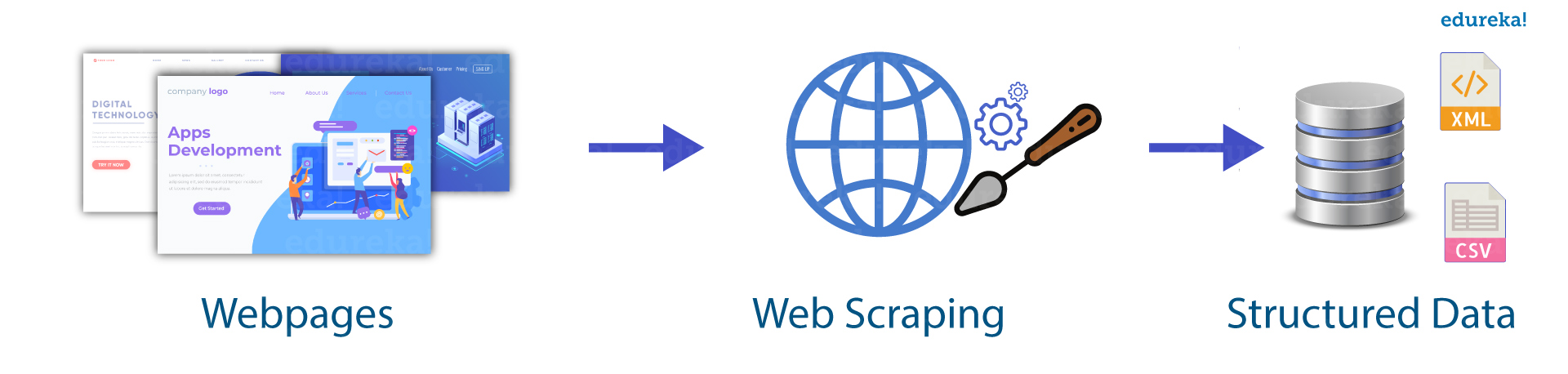
Comment faire du web scraping avec Python ?
Pour réaliser vos premiers projets de web scraping, rien de plus simple ! Il vous suffit d'avoir un ordinateur, avec la suite Python installé et une connexion internet.
Ensuite, vous allez devoir installé une ou des librairies de votre choix, énoncées ci après avec leur spécificité:
- Beautiful Soup: idéal pour démarrer, cette librairie est facile à prendre en main et à utiliser. Les opérations sont faciles à réaliser, l'extraction est assez performante en terme de temps de calcul. C'est en réalité une surcouche de la librairie LXML adaptée au langage HTML pour extraire les données dont vous avez besoin. Cependant, pour des usages avancés tel que du login, de l'interaction avec les pages web ou encore de l'extraction de donnée générée par du Javascript "dynamique", il vous faudra passer au niveau supérieur.
- Scrapy: un framework de web scraping / crawling à part entière. Comme tout framework, il demande de respecter une architecture de projet et de codage assez précise, cependant une fois ce dernier pris en main vous serez en mesure de réaliser des projets complets d'extraction de donnée avec des actions avancées tel que du login, de l'interaction avec les pages web etc. La performance est relativement bonne avec ce framework.
- Selenium: outil de test automatisé. A la base, Selenium est utilisé comme outil de test automatisé avec des interfaces pour cliquer sur des boutons, interagir avec des éléments etc. Cependant son usage a été quelque peu "détourné" pour en faire un outil d'extraction et d'automatisation d'action web. Assez facile à prendre en main, cependant ses performances sont très limitées car vous devez interagir directement avec un navigateur ainsi qu'attendre l'affichage des différents éléments HTML.
L'idéal pour un projet réussi est de bien penser à la source à extraire, ainsi que réfléchir aux règles de calculs les moins coûteuses c'est à dire récupérer une page HTML en premier lieu, puis effectuer l'extraction ou effectuer l'extraction en temps réel. Pas de réponse générique adaptée à tout le monde, tout dépend de quelle source est à extraire et du site web lui même à scraper. Il est même possible que vous soyez amené à combiner ces 3 librairies, avec également des clients de base de donnée ou d'autres librairies tel que pandas / numpy pour le passage à des formats de fichiers utilisables par d'autres équipes de l'entreprise.
Besoin de plus de détail sur "Web Scraping en Python, une valeur ajoutée pour votre entreprise" ?
Vous pouvez nous contacter par téléphone, ou par mail pour plus de détail concernant cet article. Nous vous proposons également des formations pour à des prix défiant toute concurrence, afin que vous deveniez un vrai professionnel du digital.